Die teuerste Bibliothek der Welt
Ihre Datenplattform ist eine Bibliothek. Eine beeindruckende, akribisch katalogisierte Bibliothek im Petabyte-Maßstab. Und niemand trifft damit Entscheidungen schnell genug.
Die AI-at-Work-Studie des World Economic Forum prognostiziert, dass KI bis 2030 weltweit 92 Millionen Arbeitsplätze verdrängen und gleichzeitig 170 Millionen neue schaffen wird. Der Nettogewinn ist real — aber nur für Organisationen, die aus Erkenntnissen handeln können, statt sie nur zu speichern. Die Forschung des MIT Sloan zu Scaling AI for Results bestätigt, was ich in der Praxis immer wieder sehe: Die Lücke zwischen KI-Pilotprojekten und Unternehmenswert ist kein Modellproblem. Es ist ein Architekturproblem.
Wir haben fünfzehn Jahre damit verbracht, die Daten-Pipelines zu perfektionieren: Data Lakes, Lakehouses, Medallion-Architekturen, Streaming-Ingestion. Alles für dasselbe Ziel optimiert: Daten verfügbar machen. Verfügbarkeit ist heute Pflicht, nicht Kür. Die Frage lautet nicht mehr „Komme ich an die Daten?“, sondern „Trifft das System eine gute Entscheidung, rechtzeitig, mit angemessener Kontrolle?“
Das ist ein grundlegend anderes Designproblem. Und die meisten Unternehmensarchitekturen sind dafür schlicht nicht gebaut.
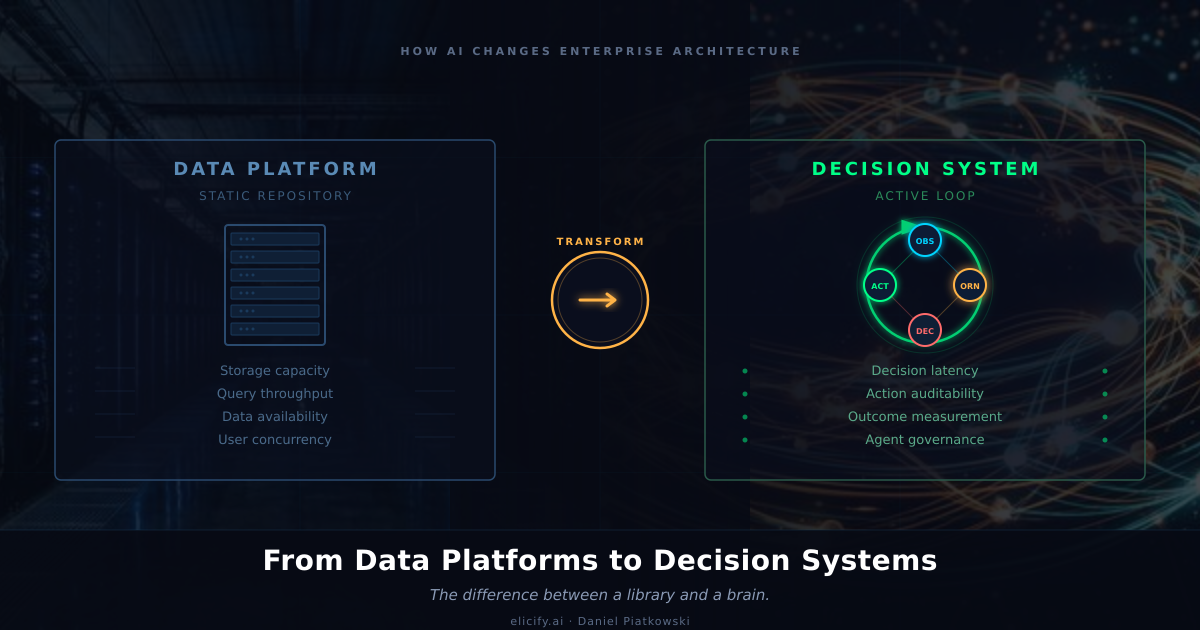
Diagnose: Worauf Datenplattformen tatsächlich optimieren
Datenplattformen sind Infrastruktur für Speicherung, Verarbeitung und Bereitstellung. Das beherrschen sie hervorragend. Databricks Unity Catalog, die Governance-Schicht von Snowflake, der gesamte moderne Data Stack — alle entworfen um eine Kernannahme herum: Menschen treffen die Entscheidungen, die Plattform liefert ihnen saubere Daten zu.
Diese Annahme prägt alles. Batch-Verarbeitungsfenster sind akzeptabel, weil ein Mensch das Dashboard morgen früh prüft. Eventual Consistency ist in Ordnung, weil dem Analysten schon auffallen wird, wenn die Zahlen nicht stimmen. Lineage-Tracking existiert, um Auditoren zufriedenzustellen, nicht um autonome Agenten in Echtzeit mit Provenance zu versorgen.
Die Architektur optimiert für Durchsatz und Verfügbarkeit. Wie viele Daten können wir verarbeiten? Wie schnell beantworten wir eine Abfrage? Wie viele gleichzeitige Nutzer kann das Warehouse bedienen? Das sind die richtigen Fragen für eine Welt, in der Menschen am Ende jeder Datenpipeline sitzen und ihr Urteil anwenden, bevor gehandelt wird.
Diese Welt geht zu Ende.
Wenn ein KI-Agent eine Kundenrückerstattung verarbeitet, ein Kreditlimit empfiehlt oder eine Lieferkette umroutet, reichen die Garantien der Datenplattform nicht aus. Der Agent braucht nicht den Batch-Refresh von gestern. Er braucht den aktuellen Zustand, Entscheidungsgrenzen, Audit Trails und Feedback-Schleifen. Er muss nicht nur wissen, was die Daten sagen, sondern welche Befugnisse er hat, wo die Schwelle für autonomes Handeln liegt und wohin er eskalieren muss.
Stellen Sie sich vor: Ein Pricing-Agent arbeitet mit einem 24-Stunden-Batch-Refresh, während Wettbewerber in Echtzeit anpassen. Drei Tage margenvernichtende Entscheidungen, bevor es jemand bemerkt. Das Modell ist in Ordnung. Die Architektur versagt. Das ist nicht hypothetisch — es ist die vorhersehbare Folge davon, KI-Agenten auf einer Infrastruktur zu betreiben, die auf den Entscheidungsrhythmus von Menschen ausgelegt war.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph LR
subgraph DP["DATENPLATTFORM (optimiert für)"]
A1["Speicher-\nkapazität"]
A2["Query-\nDurchsatz"]
A3["Daten-\nverfügbarkeit"]
A4["Gleichzeitige\nNutzer"]
end
subgraph DS["ENTSCHEIDUNGSSYSTEM (optimiert für)"]
B1["Entscheidungs-\nlatenz"]
B2["Aktions-\nNachvollziehbarkeit"]
B3["Ergebnis-\nMessung"]
B4["Agent-\nGovernance"]
end
DP -->|"Notwendig, aber\nnicht hinreichend"| DS
style A1 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style A2 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style A3 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style A4 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style B1 fill:#1a2540,stroke:#ffb347,color:#ffffff
style B2 fill:#1a2540,stroke:#ffb347,color:#ffffff
style B3 fill:#1a2540,stroke:#ffb347,color:#ffffff
style B4 fill:#1a2540,stroke:#ffb347,color:#ffffff
style DP fill:#0a0f1e,stroke:#00d4ff,color:#00d4ff
style DS fill:#0a0f1e,stroke:#ffb347,color:#ffb347
Perspektivwechsel: Was Kampfpiloten längst wussten
In den 1950er Jahren ging US-Air-Force-Colonel John Boyd der Frage nach, warum amerikanische Piloten in Korea ein Abschussverhältnis von 10:1 erreichten, obwohl ihre Maschinen einen schlechteren Wenderadius hatten. Seine Antwort hatte nichts mit den Flugzeugen zu tun. Es ging um Entscheidungsgeschwindigkeit.
Boyd entwickelte die OODA-Schleife: Observe, Orient, Decide, Act. Der Pilot, der diese Schleife schneller durchlief, gewann das Gefecht — nicht wegen besserer Waffen, sondern weil er innerhalb des Entscheidungszyklus seines Gegners operierte. Bis sich der Gegner auf die neue Lage eingestellt hatte, hatte sich die Lage längst wieder verändert.
Die Unternehmens-KI-Architektur läuft heute auf dasselbe Muster zu, ohne es so zu nennen.
Jedes agentische System, das ich in Produktion gesehen habe, folgt Boyds Schleife. Der Agent beobachtet (nimmt den aktuellen Zustand aus Streaming-Daten, APIs und Events auf). Er orientiert sich (legt Kontext an: Geschäftsregeln, historische Muster, Schwellenwerte für autonomes Handeln). Er entscheidet (wählt eine Aktion innerhalb seiner Befugnisgrenze). Er handelt (führt die Entscheidung aus und erfasst das Ergebnis). Dann fließt das Ergebnis zurück in die Beobachtung, und die Schleife läuft weiter.
Die Parallele ist nicht dekorativ. Boyds Kerneinsicht war, dass die Orient-Phase — in der man Informationen gegen das eigene mentale Modell abgleicht — der Ort ist, an dem Wettbewerbsvorteil entsteht. In der Unternehmens-KI ist Orientierung der Ort, an dem der Agent Governance, Kontext und Domänenwissen anwendet. Macht man das falsch, hat man ein schnelles System, das mit hoher Konfidenz schlechte Entscheidungen trifft. Macht man es richtig, hat man etwas, das menschliche Entscheidungsfindung in puncto Geschwindigkeit tatsächlich übertrifft.
Ob das auf jeden Use Case im Unternehmen sauber passt, bin ich nicht sicher. Manche Entscheidungen sollten langsam und abwägend bleiben. Aber für die 80 % der operativen Entscheidungen, die bekannten Mustern mit klaren Grenzen folgen, ist die OODA-Architektur bemerkenswert wirksam.
Framework: Die Architektur der Entscheidungsschleife
So sieht das Modell aus. Ein Entscheidungssystem hat vier Schichten, jede einer Phase der Schleife zugeordnet. Die Datenplattform verschwindet nicht — sie wird zum Fundament, auf dem die Entscheidungsschichten aufsetzen.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph TD
O["OBSERVE\nStreaming-Ingestion, Event-Erfassung,\nEchtzeit-Zustand"] --> OR["ORIENT\nKontext-Engine: Regeln, Schwellen,\nhistorische Muster, Konfidenzwerte"]
OR --> D["DECIDE\nAgent wählt Aktion innerhalb\nder Befugnisgrenze"]
D --> A["ACT\nEntscheidung ausführen, Ergebnis erfassen,\nvolle Spur protokollieren"]
A -->|"Feedback-Schleife"| O
DP["DATENPLATTFORM\nSpeicher, Verarbeitung, Governance,\nKatalog"] -.->|"Speist"| O
A -.->|"Ergebnisse gespeichert"| DP
style O fill:#1a2540,stroke:#00d4ff,color:#ffffff,stroke-width:2px
style OR fill:#1a2540,stroke:#ffb347,color:#ffffff,stroke-width:2px
style D fill:#1a2540,stroke:#00ff88,color:#ffffff,stroke-width:2px
style A fill:#1a2540,stroke:#ff6b6b,color:#ffffff,stroke-width:2px
style DP fill:#0a0f1e,stroke:#ffffff,color:#ffffff,stroke-width:1px
Schicht 1: Observe. Ersetzen Sie Batch-ETL als primären Input durch Streaming-Event-Erfassung. Die Datenplattform übernimmt weiterhin rechenintensive analytische Workloads, doch das Entscheidungssystem braucht den aktuellen Zustand. Das heißt: Change Data Capture aus operativen Systemen, Event-Streams aus Kundeninteraktionen, Echtzeit-Marktdaten. Databricks Delta Live Tables oder Snowflake Streams leisten das gut — die Technologie ist da. Die Lücke ist, dass die meisten Unternehmen Streaming nach wie vor als Ausnahme behandeln und nicht als Standardpfad für Eingangsdaten.
Schicht 2: Orient. Diese Schicht fehlt den meisten Architekturen komplett. Orientierung ist der Ort, an dem rohe Signale zu entscheidungsfähigem Kontext werden. Sie umfasst Geschäftsregeln (dieser Kunde gehört zu einem regulierten Segment), historische Muster (vergleichbare Anfragen führten in 30 % der Fälle zu Chargebacks), Konfidenzkalibrierung (das Modell ist zu 72 % konfident — liegt das über der Schwelle für autonomes Handeln?) und Befugnisgrenzen (der Agent darf bis 5.000 Euro freigeben; darüber wird eskaliert). Ohne diese Schicht treffen Agenten Entscheidungen im luftleeren Raum.
Schicht 3: Decide. Der Agent wählt eine Aktion und legt sich darauf fest. Frameworks wie OpenClaw und LangGraph kodieren das als Agenten-Runtime: planen, Tools ausführen, Evidenz prüfen, fortfahren. Die kritische Designentscheidung lautet, jede Entscheidung explizit zu machen und zu protokollieren — nicht nur die Aktion, sondern die Begründung, die geprüften Alternativen und den Konfidenzniveau. Erst das macht das System auditierbar.
Schicht 4: Act. Entscheidung ausführen und die Schleife schließen. Das Ergebnis — hat die Rückerstattung Abwanderung reduziert? Ist die umgeleitete Sendung pünktlich angekommen? — fließt zurück in die Beobachtungsschicht. So lernt das System. Nicht durch periodisches Modell-Retraining, sondern durch kontinuierliche Messung der Entscheidungsqualität.
Das Schwierigste ist nicht der Bau einer einzelnen Schicht. Es ist, sie zu einer durchgängigen Schleife mit durchgängiger Governance über alle Schichten hinweg zu verbinden. Die meisten Unternehmen, mit denen ich arbeite, haben Fragmente: irgendwo Streaming, anderswo einen Agent-Prototyp, in noch einem System eine Regel-Engine. Die Integration ist die Architektur.
Anwendung: Die Entscheidungsschleife von Lemonade in der Schadensregulierung
Lemonade Insurance hat genau diese Architektur mit seinem KI-Agenten für die Schadensregulierung AI Jim umgesetzt. Vorher liefen Schadensfälle durch den branchenüblichen Prozess: Eingang, Warteschlange, menschliche Prüfung anhand der Versicherungsbedingungen. Einfache Fälle verbrauchten dieselbe Prüfzeit wie komplexe Schäden.
Lemonade hat keinen KI-Agenten auf den bestehenden Prozess gesetzt. Sie haben die Architektur rund um die Entscheidung neu gezeichnet.
Observe: Schadensfälle kommen über die App herein — Foto-Uploads, Schilderungen, strukturierte Datenerfassung. Alles wird als Event erfasst und fließt in Echtzeit in die KI-Entscheidungspipeline, nicht im Batch.
Orient: AI Jim reichert jeden Fall mit Kontext an: Deckungsprüfung anhand der Police, Betrugsrisiko-Scoring (auf Basis historischer Schadensmuster), Schadensbewertung per Computer Vision und eine Befugnismatrix, die definiert, was der Agent autonom freigeben darf.
Decide: Für Fälle innerhalb definierter Parameter — Standarddeckung, Betrugsrisiko unter Schwelle — gibt AI Jim frei und löst die Auszahlung aus. Der Rekord: ein Schadensfall in 2 Sekunden reguliert. Liegt der Fall oberhalb dieser Schwellen, wird er an einen menschlichen Sachbearbeiter weitergeleitet — mit dem vollständigen Kontext bereits vorbereitet. Der Agent markiert den Fall nicht nur, er begründet, warum er eskaliert.
Act: Auszahlung wird ausgelöst, Kundenbenachrichtigung versendet, und das Ergebnis (Fall wieder geöffnet? Kunde beschwert? Betrug später erkannt?) fließt zurück in das Modell. 96 % der Erstmeldungen werden inzwischen von KI bearbeitet, 55 % der Fälle vollständig autonom.
Der Trade-off ist eine erhebliche Vorabinvestition in die Orient-Schicht — Geschäftsregeln, Schwellen und Eskalationslogik in die Architektur kodieren, statt sie in den Köpfen der Sachbearbeiter zu lassen. Diese Wissenserfassung war das eigentliche Projekt. Der KI-Anteil war vergleichsweise unkompliziert.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph LR
subgraph BEFORE["VORHER: Prozessarchitektur"]
C1["Schadensfall\ngeht ein"] --> Q1["Warteschlange\n(Tage)"] --> H1["Mensch prüft\nalles"] --> P1["Auszahlung\noder Ablehnung"]
end
subgraph AFTER["NACHHER: Entscheidungsschleife"]
C2["Schadensfall\nals Event"] --> CTX["Orient:\nKontext-Engine"] --> DEC{"Decide:\ninnerhalb der\nGrenze?"}
DEC -->|"Ja"| AUTO["Auto-Freigabe\n< 4 Stunden"]
DEC -->|"Nein"| HUM["Mensch +\nvoller Kontext"]
AUTO --> FB["Feedback-\nSchleife"]
HUM --> FB
FB -->|"Ergebnisse"| CTX
end
style C1 fill:#1a2540,stroke:#ffffff,color:#ffffff
style Q1 fill:#2a1a1a,stroke:#ff6b6b,color:#ff6b6b
style H1 fill:#1a2540,stroke:#ffffff,color:#ffffff
style P1 fill:#1a2540,stroke:#ffffff,color:#ffffff
style C2 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style CTX fill:#1a2540,stroke:#ffb347,color:#ffffff
style DEC fill:#1a2540,stroke:#00ff88,color:#ffffff
style AUTO fill:#0a2a1e,stroke:#00ff88,color:#00ff88
style HUM fill:#1a2540,stroke:#00d4ff,color:#ffffff
style FB fill:#1a2540,stroke:#ffb347,color:#ffffff
style BEFORE fill:#0a0f1e,stroke:#ff6b6b,color:#ff6b6b
style AFTER fill:#0a0f1e,stroke:#00ff88,color:#00ff88
Konsequenz: Die Architektur ist die Strategie
Der Wechsel von Datenplattformen zu Entscheidungssystemen ist kein Technologie-Upgrade. Es ist eine architektonische Neuausrichtung um eine andere Wertlogik herum. Die Datenplattform fragt: Wie verwalten wir Information? Das Entscheidungssystem fragt: Wie produzieren wir gute Ergebnisse, schnell und nachvollziehbar?
Jedes Unternehmen verfügt bereits über die Dateninfrastruktur. Was fehlt, ist die Orient-Schicht — das kodierte Geschäftswissen, die Befugnisgrenzen, die Feedback-Schleifen, die aus Rohdaten gesteuertes Handeln machen. Diese Schicht ist der neue Wettbewerbsvorteil. Nicht das Modell, nicht die Daten, nicht die Rechenleistung. Die Architektur der Entscheidung selbst.
Quellen
- World Economic Forum, AI at Work Insights, Januar 2025
- MIT Sloan Management Review, Scaling AI for Results, Januar 2025
- John Boyd, „Patterns of Conflict“ (1986) — ursprüngliche OODA-Loop-Doktrin
- Lemonade Insurance: AI Jim stellt neuen Weltrekord auf
Daniel Piatkowski — Data & Analytics-Veteran, der AI-native Unternehmen prägt.