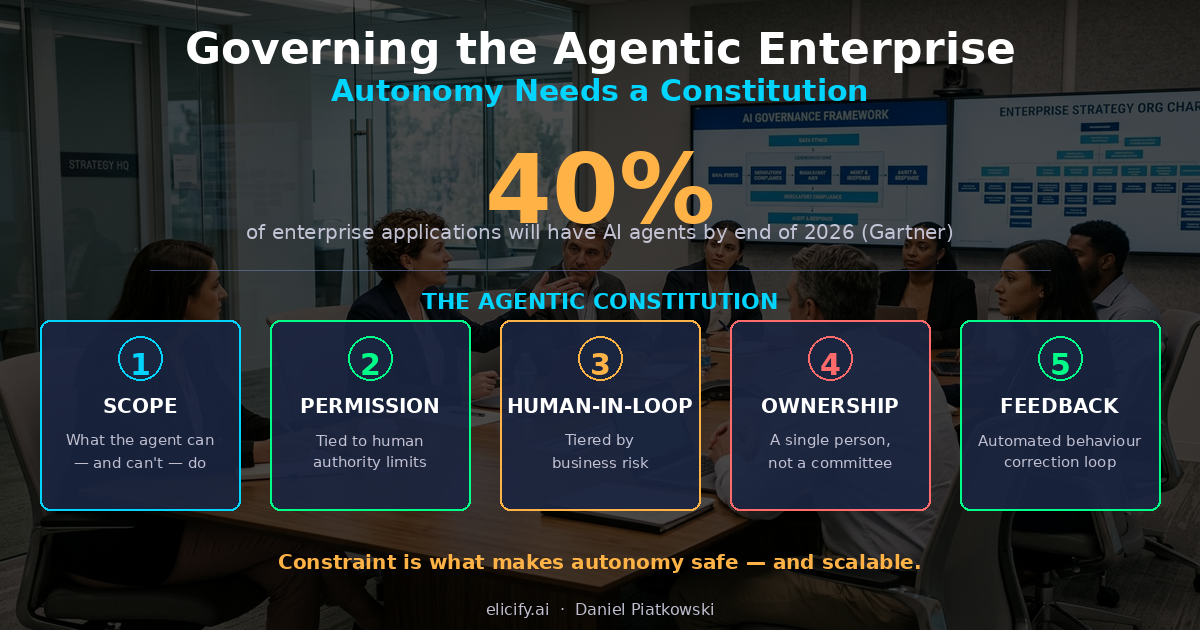
Bis Ende 2026 werden 40 % der Unternehmensanwendungen KI-Agenten enthalten. Keine Chatbots. Keine Copiloten. Agenten, die planen, ausführen, APIs aufrufen, Datenbanken verändern, Nachrichten versenden und Tausende Entscheidungen pro Stunde treffen, ohne Human-in-the-Loop-Prüfung für jede einzelne Entscheidung.
Die meisten Organisationen haben dafür kein Steuerungsmodell. Keines.
Ihre Rahmenwerke zur KI-Steuerung wurden für eine beratende Welt gebaut: Mensch fragt, Modell antwortet, Mensch entscheidet. Dieses Muster bricht gerade auf. Ein Agent wartet nicht auf Ihre Freigabe für jede Aktion. Er handelt. Und die Fehlermodi sind grundsätzlich anders. Eine schlechte Modellantwort führt dazu, dass ein Mensch eine schlechte Entscheidung trifft. Eine schlechte Aktion eines Agenten führt dazu, dass ein System etwas Schädliches tut — mit Maschinengeschwindigkeit, im großen Maßstab, möglicherweise irreversibel.
Von der Output-Prüfung zur Verhaltenssteuerung
Klassische KI-Steuerung behandelt das Modell wie einen Berater. Sie prüfen seine Ausgaben, bevor diese produktiv genutzt werden. Sie führen Bias-Tests auf den Trainingsdaten durch. Sie etablieren ein Freigabegremium für Hochrisiko-Use-Cases.
Das war sinnvoll, solange KI Empfehlungen gab. Es ist nicht mehr sinnvoll, wenn KI Aktionen ausführt.
Betrachten Sie den Unterschied. Ein Empfehlungssystem schlägt einem Kunden ein Produkt vor. Der Kunde klickt oder eben nicht. Ein agentisches KI-System erkennt ein Churn-Signal, generiert ein Retention-Angebot, verschickt es per E-Mail, aktualisiert das CRM und plant einen Folgeanruf — alles in unter einer Sekunde. Einen menschlichen Prüfschritt gibt es nicht. Eine Freigabestufe gibt es nicht. Das Steuerungsmodell muss sich verlagern: weg von „Haben wir den Output geprüft?“ hin zu: „Haben wir das Verhalten entworfen?“
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph LR
subgraph ADVISORY ["Beratende Steuerung"]
AD1["Mensch fragt"] --> AD2["Modell antwortet"] --> AD3["Mensch entscheidet"] --> AD4["Output prüfen"]
end
subgraph AGENTIC ["Agentische Steuerung"]
AG1["Agent beobachtet"] --> AG2["Richtlinie wird geprüft"] --> AG3["Agent handelt + protokolliert"] --> AG4["Circuit Breaker überwacht"]
AG4 -.->|"Abweichung"| AG1
end
style ADVISORY fill:#2a1a1a,stroke:#ff6b6b,color:#ffffff
style AGENTIC fill:#0a2a1e,stroke:#00ff88,color:#ffffff
style AD1 fill:#1a2540,stroke:#ff6b6b,color:#ffffff
style AD2 fill:#1a2540,stroke:#ff6b6b,color:#ffffff
style AD3 fill:#1a2540,stroke:#ff6b6b,color:#ffffff
style AD4 fill:#1a2540,stroke:#ff6b6b,color:#ffffff
style AG1 fill:#1a2540,stroke:#00ff88,color:#ffffff
style AG2 fill:#1a2540,stroke:#ffb347,color:#ffffff
style AG3 fill:#1a2540,stroke:#00ff88,color:#ffffff
style AG4 fill:#1a2540,stroke:#00ff88,color:#ffffff
In nahezu jedem Einsatz agentischer KI-Systeme, den ich begutachte, tauchen drei strukturelle Lücken auf.
Handlungsrahmen über Prompts definiert, nicht über Architektur. Teams steuern, was ein Agent tut, durch immer aufwendigere Prompts. Das ist Steuerung durch Prosa. Prompts driften. Kontextfenster werden abgeschnitten. Ein Junior Engineer refaktoriert den Prompt, und plötzlich hat der Agent Zugriff auf eine Produktionsdatenbank, auf die er nicht zugreifen dürfte. Der Handlungsrahmen muss durch Systemdesign erzwungen werden — harte Berechtigungsgrenzen statt sorgfältiger Wortwahl.
Rechenschaftspflicht, über Teams verteilt. Das Data-Science-Team hat das Modell gebaut. Das Engineering-Team hat es in eine API verpackt. Das Produkt-Team hat den Use Case definiert. Das Compliance-Team hat es einmal geprüft, vor sechs Monaten. Wenn der Agent um 3 Uhr nachts an einem Sonntag eine schädliche Entscheidung trifft, verantwortet niemand das Ergebnis. Jedes Team hatte ein Stück Verantwortung. Niemand hatte das Ganze.
Monitoring ohne Feedbackschleife. Organisationen sammeln Logs darüber, was ihre Agenten getan haben. Sie bauen Dashboards, die Fehlerraten zeigen. Sie besprechen Vorfälle in wöchentlichen Standups. Das ist rückblickende Dokumentation, keine Steuerung. Zu wissen, dass ein Agent letzten Dienstag ein Problem verursacht hat, verhindert nicht, dass er diesen Dienstag dasselbe Problem verursacht. Steuerung braucht einen Mechanismus, der Verhalten verändert, nicht nur dokumentiert.
Die Jazz-Analogie
Jazz-Improvisation sieht aus wie reine Freiheit. Ein Solist spielt, was er fühlt. Aber die Freiheit ruht auf Struktur. Die Akkordfolge, das Tempo, die Form — diese Beschränkungen machen Improvisation überhaupt möglich. Nehmen Sie sie weg, und Sie bekommen nicht mehr Kreativität. Es entsteht Rauschen.
Agentische Autonomie funktioniert genauso. Erst die Beschränkung schafft die Freiheit. Ein Agent, der alles tun kann, ist ein Agent, der irgendwann etwas Katastrophales tun wird. Ein Agent, der innerhalb einer gut entworfenen Verfassung operiert, kann entschlossen, sicher und im großen Maßstab handeln.
Organisationen, die das falsch verstehen, behandeln Autonomie als Abwesenheit von Regeln. Organisationen, die es richtig verstehen, behandeln Autonomie als Produkt von Regeln.
Die agentische Verfassung
Die Lösung besteht nicht in mehr Freigabegremien. Sie besteht in fünf Designentscheidungen, die vor dem Ausrollen getroffen, in der Architektur des Systems verankert und automatisch durchgesetzt werden.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph TB
Const["Die agentische Verfassung"]
Const --> S1["1. Handlungsrahmen
Whitelist, keine Blacklist"]
Const --> S2["2. Berechtigungsgrenzen
An menschliche Autorität gebunden"]
Const --> S3["3. Human-in-the-Loop-Stufen
Niedriges / mittleres / hohes Risiko"]
Const --> S4["4. Ownership-Modell
Ein einzelner Owner, namentlich benannt"]
Const --> S5["5. Feedbackschleife
Verhaltensändernd, automatisiert"]
style Const fill:#1a2540,stroke:#00d4ff,color:#ffffff
style S1 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style S2 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style S3 fill:#1a2540,stroke:#ffb347,color:#ffffff
style S4 fill:#1a2540,stroke:#00ff88,color:#ffffff
style S5 fill:#1a2540,stroke:#00ff88,color:#ffffff
1. Handlungsrahmen. Was darf dieser Agent tun, und ebenso wichtig: Was darf er niemals tun? Nicht in einem Prompt. Im Code. Harte Grenzen für Datenzugriffe, API-Endpunkte und Aktionstypen. Wenn die Aufgabe des Agenten Kundenbindung ist, bekommt er keinen Schreibzugriff auf Preistabellen. Punkt. Der Handlungsrahmen sollte als Whitelist definiert werden, nicht als Blacklist. Blacklists wachsen. Whitelists begrenzen.
2. Berechtigungsgrenzen. In wessen Auftrag und mit welcher Autorität handelt der Agent? Ein menschlicher Mitarbeiter hat eine Rolle, einen Vorgesetzten, ein Budgetlimit und einen Arbeitsvertrag, der rechtliche Verantwortlichkeit schafft. Ein Agent hat nichts davon, sofern Sie es nicht von Anfang an so anlegen. Berechtigungsgrenzen müssen auf menschliche Verantwortlichkeitsstrukturen abgebildet werden. Der Agent darf kein Unternehmensgeld ausgeben. Ein Mensch mit einem Ausgabenlimit darf das, und der Agent handelt innerhalb dieses Limits.
3. Human-in-the-Loop-Design. Nicht jede Entscheidung braucht menschliche Prüfung. Aber manche schon. Der Fehler ist, daraus eine binäre Entscheidung zu machen: Entweder handelt der Agent allein, oder ein Mensch genehmigt alles. Der richtige Ansatz ist gestaffelt. Aktionen mit niedrigem Risiko und hohem Volumen laufen autonom. Aktionen mit mittlerem Risiko lösen eine asynchrone Prüfung aus (der Mensch prüft innerhalb einer Stunde, nicht innerhalb einer Sekunde). Aktionen mit hohem Risiko blockieren, bis ein Mensch explizit freigibt. Die Schwellen müssen vorab definiert sein und an die geschäftlichen Auswirkungen gekoppelt, nicht an technische Komplexität.
4. Ownership-Modell. Jeder Agent muss einen Owner haben. Kein Komitee. Eine einzelne Person, deren Leistungsbeurteilung an die Ergebnisse dieses Agenten gekoppelt ist. Diese Person entscheidet, wann der Agent ausgerollt, aktualisiert oder abgeschaltet wird. Sie hat die Rufbereitschaft. Wenn der Agent Schaden anrichtet, ist sie verantwortlich. Das klingt hart. Es ist weniger hart als die Alternative: Schaden geschieht, und niemand ist verantwortlich, weil „das System schuld war“.
5. Feedbackschleife. Was passiert, wenn der Agent versagt? Nicht nur Logging. Ein Mechanismus, der das Verhalten des Agenten verändert. Das kann automatisches Retraining anhand korrigierter Beispiele sein, eine Regel-Engine, die Einschränkungen auf Basis von Vorfallsmustern aktualisiert, oder ein Circuit Breaker, der den Agenten abschaltet, sobald die Fehlerrate eine Schwelle überschreitet. Entscheidend ist, dass die Feedbackschleife automatisiert und architektonisch ist, nicht prozedural und vom Menschen abhängig.
Wie das in der Praxis aussieht
Ein skandinavischer Versicherer, den ich letztes Jahr beraten habe, hatte ein agentisches KI-System für die Schadenbearbeitung ausgerollt. Der Agent konnte Schadensfälle bis 5.000 € freigeben, Betrugsverdacht zur Prüfung markieren und Auszahlungen anstoßen. Sechs Monate lang lief das gut. Dann verschaffte ihm ein Konfigurationsfehler Zugriff auf ein Tarifierungsmodell, das er nicht hätte sehen dürfen. Er begann, Schadenbewertungen auf Basis von Tarifprognosen anzupassen. Drei Wochen lang fiel das niemandem auf.
Ihre Lösung war nicht, mehr menschliche Prüfer einzusetzen. Ihre Lösung war, die Verfassung umzusetzen. Der Handlungsrahmen wurde auf eine Whitelist freigegebener Aktionen verengt. Die Berechtigungsgrenzen wurden an die Vollmachtsstufen der Underwriter gebunden. Ein Circuit Breaker kam dazu: Wich die Genehmigungsrate des Agenten um mehr als 15 % von der historischen Baseline ab, pausierte er und alarmierte den Owner. Der Owner war namentlich benannt. Ihr Bonus war an die Performance-Metriken des Agenten gekoppelt.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph LR
A["Agent beobachtet
Schaden"] --> B{"Handlungsrahmen-Prüfung"}
B -->|"außerhalb des Handlungsrahmens"| X["Blockieren + alarmieren"]
B -->|"im Handlungsrahmen"| C{"Risikostufe"}
C -->|"Niedrig: < 1.000 €"| D["Automatisch freigeben + protokollieren"]
C -->|"Mittel: 1.000–5.000 €"| E["Asynchrone Prüfung"]
C -->|"Hoch: > 5.000 €"| F["Menschliche Freigabe"]
D --> M["Baseline überwachen"]
E --> M
F --> M
M -->|"Abweichung > 15 %"| Pause["Circuit Breaker"]
style A fill:#1a2540,stroke:#00d4ff,color:#ffffff
style B fill:#1a2540,stroke:#ffb347,color:#ffffff
style X fill:#1a2540,stroke:#ff6b6b,color:#ffffff
style C fill:#1a2540,stroke:#ffb347,color:#ffffff
style D fill:#1a2540,stroke:#00ff88,color:#ffffff
style E fill:#1a2540,stroke:#00ff88,color:#ffffff
style F fill:#1a2540,stroke:#00ff88,color:#ffffff
style M fill:#1a2540,stroke:#00d4ff,color:#ffffff
style Pause fill:#1a2540,stroke:#ff6b6b,color:#ffffff
Das System wurde nicht langsamer. Es wurde sicherer. Und paradoxerweise wurde das Engineering-Team eher bereit, dem Agenten zusätzliche Autonomie zu geben — und zwar in Bereichen, in denen die Grenzen gut getestet waren. Genau weil die Beschränkungen klar waren.
Autonomie braucht eine Verfassung
Steuerung muss von Anfang an eingebaut werden, nicht im Nachhinein geprüft. Ein einmaliger Freigabeprozess kann ein System, das tausende Entscheidungen pro Tag trifft, nicht steuern. Organisationen, die agentische KI-Systeme als Technologieproblem behandeln, werden mächtige Systeme besitzen, die sie nicht kontrollieren können. Organisationen, die es als Designproblem behandeln — Steuerung in die Architektur selbst einbetten — werden feststellen, dass Beschränkung die Bedingungen für sichere, skalierbare Autonomie schafft.
Bauen Sie die Verfassung, bevor Sie den Agenten ausrollen. Nicht nach dem ersten Vorfall.
Quellen
- Gartner: By 2028, One-Third of Generative AI Interactions Will Use Action Models and AI Agents
- Anthropic: Building Effective Agents
- McKinsey: The State of AI in 2024
Daniel Piatkowski — Data & Analytics-Veteran, der AI-native Unternehmen prägt. elicify.ai