Geschäftlicher Kontext
Jedes Gespräch über Enterprise-KI läuft früher oder später gegen dieselbe Wand: Das Modell funktioniert in der Demo, scheitert aber in der Produktion. Der Grund ist nicht die Modellqualität. Es liegt an allem rund um das Modell.
Der KI-Stack reift schnell. Allein in den ersten Wochen 2026 hat Anthropic Claude Opus 4.6 mit Extended Thinking veröffentlicht, Weaviate hat agent-native Query-Skills gestartet, und Qdrant hat Version 1.17 mit Verbesserungen bei der Hybrid-Suche herausgebracht. Das sind keine inkrementellen Updates. Sie zeigen: Die Branche konvergiert zu einer geschichteten Architektur für KI – jede Schicht löst ein konkretes Produktionsproblem, das Modelle allein nicht beheben können.
Das Problem
Was ich in Enterprise-KI-Deployments immer wieder sehe: Ein Team baut einen Proof of Concept. Das Modell läuft gut. Die Führung gibt grünes Licht für die Produktion. Dann kommt die Realität.
Das Modell halluziniert, weil es keinen strukturierten Zugriff auf Unternehmensdaten hat. Es ruft die falsche API auf, weil es keine Tool-Registry gibt. Wenn es scheitert, kann niemand nachvollziehen, warum, weil es keine Observability gibt. Wenn es erfolgreich ist, kann niemand belegen, dass es gesteuerte Daten genutzt hat, weil es keinen Semantic Layer gibt. Und wenn das zweite Team seinen eigenen Agenten baut, löst es all diese Probleme anders – und schafft so ein fragmentiertes Geflecht aus maßgeschneiderten Einzelintegrationen.
Das ist Punkt-zu-Punkt-Verdrahtung. Jedes Agent-Team erfindet das Rad neu – eigene Retrieval-Pipeline, eigene Tool-Connectors, eigene Evaluations-Skripte. Dieses Muster ist nicht haltbar. Unternehmen verbrennen routinemäßig sechs Monate damit, Integrationsarbeit zu leisten, die eigentlich gemeinsame Infrastruktur sein sollte.
Die Lösung sind nicht bessere Modelle. Es sind standardisierte Schichten.
Die Lösung: Acht Schichten des KI-Stacks
Die Netzwerkwelt hat ein identisches Problem vor vierzig Jahren gelöst. Vor dem OSI-Modell baute jeder Netzwerkanbieter proprietäre End-to-End-Stacks. Einen IBM-Mainframe an einen DEC-Minicomputer anzubinden, erforderte maßgeschneiderte Brücken auf jeder Ebene – physische Kabel, Paketformate, Session-Management, Anwendungsprotokolle. Skalieren war unmöglich, weil jede neue Verbindung ein Einzelprojekt war.
Das OSI-Modell hat das gelöst, indem es sieben standardisierte Schichten definiert hat. Jede Schicht hatte einen klaren Vertrag mit den Schichten darüber und darunter. Man konnte Ethernet auf der physischen Ebene gegen Token Ring austauschen, ohne die Anwendung anzufassen. Routing-Protokolle ließen sich ändern, ohne den E-Mail-Client neu zu schreiben. Die Schichten haben es erlaubt, Bausteine frei zu kombinieren.
Der KI-Stack braucht dieselbe Disziplin. Und sie beginnt sich abzuzeichnen.
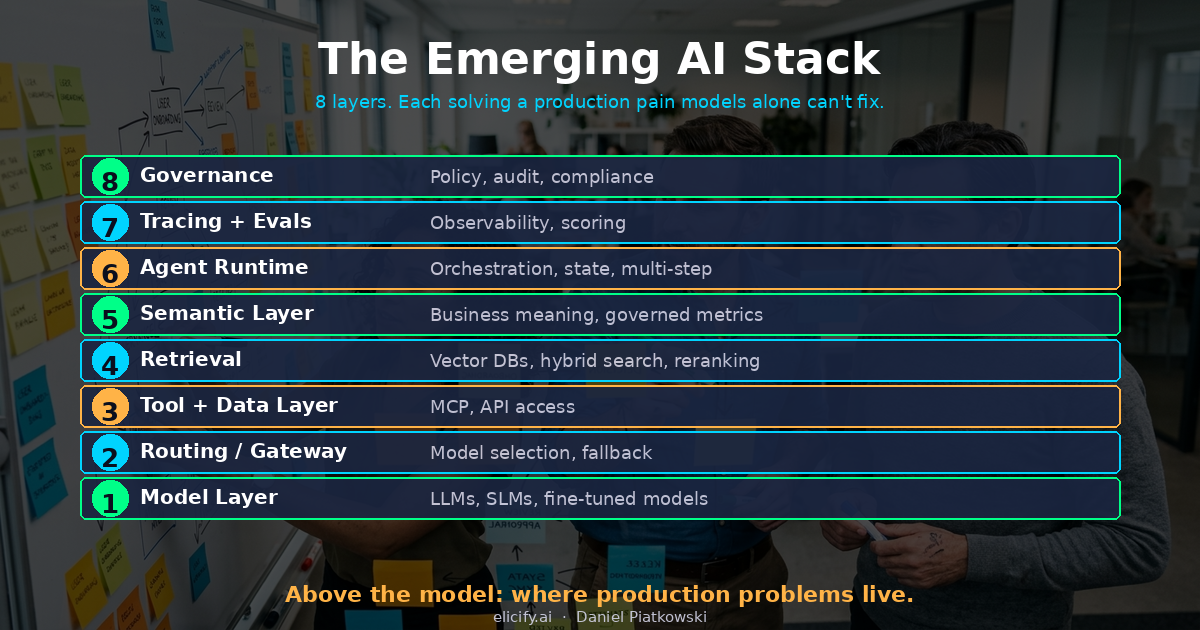
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph TB
L8["8 -- Governance
Policy-Durchsetzung, Audit, Compliance"]
L7["7 -- Tracing + Evals
Observability, Scoring, Regressionserkennung"]
L6["6 -- Agent Runtime
Orchestrierung, Zustand, mehrstufige Ausführung"]
L5["5 -- Semantic Layer
Geschäftliche Bedeutung, fachlich freigegebene Kennzahlen, Kontext"]
L4["4 -- Retrieval
Vektor-DBs, Hybrid-Suche, Reranking"]
L3["3 -- Tool- und Daten-Integration
MCP, API-Zugriff, strukturierte Tool-Nutzung"]
L2["2 -- Routing / Gateway
Modellauswahl, Fallback, Rate Limiting"]
L1["1 -- Modell-Schicht
LLMs, SLMs, fine-tuned Modelle"]
L8 --> L7
L7 --> L6
L6 --> L5
L5 --> L4
L4 --> L3
L3 --> L2
L2 --> L1
style L8 fill:#1a2540,stroke:#ff6b6b,color:#ffffff
style L7 fill:#1a2540,stroke:#ffb347,color:#ffffff
style L6 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style L5 fill:#1a2540,stroke:#00ff88,color:#ffffff
style L4 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style L3 fill:#1a2540,stroke:#ffb347,color:#ffffff
style L2 fill:#1a2540,stroke:#ffffff,color:#ffffff
style L1 fill:#1a2540,stroke:#00d4ff,color:#ffffff
Jede Schicht adressiert einen eigenen Fehlermodus:
Schicht 1 – Modell. Das Fundament. Claude, GPT, Gemini, Llama, Mistral. Reine Reasoning-Fähigkeit. Hier konzentriert sich die meiste Aufmerksamkeit, doch für Unternehmen ist es die am wenigsten differenzierende Schicht. Sie werden Modelle tauschen. Bauen Sie genau dafür.
Schicht 2 – Routing/Gateway. Modellauswahl, Fallback-Logik, Rate Limiting, Kostenkontrolle. Wenn Claude ausfällt, leiten Sie auf Gemini um. Bei einer einfachen Anfrage nehmen Sie ein kleineres Modell. Diese Schicht macht aus Modellabhängigkeit echte Modellwahlfreiheit.
Schicht 3 – Tool- und Daten-Integration. Hier lebt MCP (Model Context Protocol). Der offene Standard von Anthropic gibt Modellen einen einheitlichen Weg, Tools zu entdecken und aufzurufen – Datenbanken, APIs, Dateisysteme – über eine konsistente Schnittstelle. Vor MCP war jede Tool-Integration maßgeschneidert. MCP leistet für die KI-Tool-Nutzung das, was HTTP für die Web-Kommunikation geleistet hat: Es schafft einen gemeinsamen Protokollstandard, damit das Ökosystem zusammenspielen kann.
Schicht 4 – Retrieval. Vektordatenbanken wie Weaviate und Qdrant. Diese Schicht macht aus unstrukturiertem Wissen abfragbaren Kontext. Weaviates neue Agent-Skills bringen Retrieval näher an den autonomen Betrieb heran – die Datenbank gibt nicht nur Ergebnisse zurück, sie versteht die Absicht der Anfrage. Qdrants 1.17-Release verbessert die Hybrid-Suche, indem dichte Vektoren mit sparsem Keyword-Matching kombiniert werden. Retrieval ist nicht mehr nur „ähnliche Dokumente finden“. Es wird zu einer intelligenten Schicht.
Schicht 5 – Semantic Layer. Geschäftliche Bedeutung. Gesteuerte Definitionen. Was bedeutet „Umsatz“ in diesem Kontext? Was ist ein „aktiver Kunde“? Ohne Semantic Layer interpretieren zwei Agenten, die dieselben Daten abfragen, sie unterschiedlich. Das ist die Schicht, die die meisten Unternehmen überspringen, und sie verursacht die heimtückischsten Fehler – keine Abstürze, sondern leise falsche Antworten.
Schicht 6 – Agent Runtime. Orchestrierung, Zustandsverwaltung, mehrstufige Ausführung. OpenClaw sitzt in dieser Schicht und liefert das Gerüst, damit Agenten komplexe Workflows planen, ausführen und sich von Fehlern erholen können.
Schicht 7 – Tracing + Evals. Observability für KI. Wenn ein Agent eine schlechte Entscheidung trifft, verfolgen Sie die gesamte Kette: welches Modell, welche Tools, welche Daten, welche Reasoning-Schritte. Evaluations-Frameworks fangen Regressionen ab, bevor Nutzer es tun.
Schicht 8 – Governance. Policy-Durchsetzung, Compliance, Audit-Trails. Welche Agenten dürfen auf welche Daten zugreifen? Welche Entscheidungen brauchen menschliche Freigabe? Diese Schicht versieht alle darunterliegenden Ebenen mit Enterprise-tauglichen Kontrollen.
Umsetzung: Wo die Schichten zusammenkommen
Die echte Stärke eines geschichteten Stacks liegt darin, wie die Schichten ineinandergreifen. Ein konkreter Umsetzungspfad zeigt das.
Beginnen Sie auf Schicht 3. Stellen Sie MCP-Server für Ihre zentralen Datenquellen bereit – Ihr Data Warehouse, Ihr CRM, Ihren Dokumentenspeicher. Damit erhält jedes Modell auf Schicht 1 sofort strukturierten Zugriff auf Ihre Unternehmensdaten über ein Standardprotokoll, statt über maßgeschneiderte Connectors pro Agent.
Schicht 4 sitzt neben Schicht 3, nicht darüber. Ihre Vektordatenbank übernimmt unstrukturiertes Retrieval, während MCP strukturierte Tool-Aufrufe abwickelt. Eine gut entworfene Agent Runtime auf Schicht 6 entscheidet, welche Fähigkeit in welchem Kontext eingesetzt wird. NemoClaw verbindet Retrieval und Semantik und stellt sicher, dass Agenten auf fachlich abgesicherte Bedeutung zugreifen, nicht auf Rohdaten. Das ist der Unterschied zwischen einem Agenten, der „Dokumente zum Q4-Umsatz“ abruft, und einem, der den „Q4-Umsatz, wie ihn die Finanzabteilung als fachlich freigegebene Kennzahl definiert hat, ohne Einmalposten“ abruft.
Schicht 5 – der Semantic Layer – ist dort, wo ich in den meisten Deployments die größte Lücke sehe. Teams bauen Retrieval und Tool-Integration, überspringen aber die Schicht der geschäftlichen Bedeutung. Das Ergebnis: Agenten, die auf Daten zugreifen können, sie aber falsch deuten. Wer Databricks betreibt, deckt das mit dem Unity Catalog Semantic Layer ab. Wer Snowflake betreibt, hat mit Cortex Analyst eine vergleichbare Fähigkeit. Die Plattform ist weniger wichtig als das Prinzip: Agenten müssen auf Bedeutung zugreifen, nicht nur auf Daten.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
flowchart LR
AGENT["Agent Runtime"]
AGENT -->|"strukturierte Anfrage"| MCP["MCP-Server
Tool + Daten"]
AGENT -->|"unstrukturierte Anfrage"| VDB["Vektor-DB
Retrieval"]
MCP --> SEM["Semantic Layer
Fachlich abgesicherte Bedeutung"]
VDB --> SEM
SEM --> DW["Data Warehouse"]
SEM --> DOCS["Dokumentenspeicher"]
style AGENT fill:#1a2540,stroke:#00d4ff,color:#ffffff
style MCP fill:#1a2540,stroke:#ffb347,color:#ffffff
style VDB fill:#1a2540,stroke:#00d4ff,color:#ffffff
style SEM fill:#1a2540,stroke:#00ff88,color:#ffffff
style DW fill:#1a2540,stroke:#ffffff,color:#ffffff
style DOCS fill:#1a2540,stroke:#ffffff,color:#ffffff
Die Schichten 7 und 8 – Tracing und Governance – bilden den Kontrollrahmen für das gesamte System. Jeder Tool-Aufruf, jedes Retrieval, jede Modell-Inferenz wird protokolliert. Governance-Policies bestimmen, welche Agenten unter welchen Bedingungen auf welche Schichten zugreifen können. Ohne diese äußeren Schichten haben Sie Macht ohne Rechenschaftspflicht.
Beispiel: Wie Lemonade Insurance eine geschichtete Schadenfall-Architektur gebaut hat
Lemonade Insurance liefert ein öffentliches Beispiel dafür, wie eine geschichtete Architektur für die KI-gestützte Schadenbearbeitung in der Praxis aussieht. Ihr KI-Agent für Schadenfälle AI Jim bearbeitet 55 % der Schadenfälle vollständig automatisiert – inklusive einer Schadenregulierung in der Rekordzeit von zwei Sekunden. Die Architektur hinter dieser Geschwindigkeit ist aber kein Monolith. Sie ist geschichtet.
Entscheidend ist, was dieses System möglich macht. Die Modell-Schicht übernimmt die initiale Schadenbewertung und Betrugserkennung. Eine Retrieval-Schicht gleicht eingehende Schadenfälle mit historischen Mustern ab. Der Semantic Layer sorgt dafür, dass Begriffe wie „Totalschaden“ und „persönliches Eigentum“ über Policenarten hinweg konsistent ausgelegt werden. Governance- und Tracing-Schichten erfassen jeden Entscheidungsschritt – entscheidend für einen Versicherer, der Schadenentscheidungen gegenüber Aufsichtsbehörden begründen muss.
Gerade dieser geschichtete Ansatz macht Lemonades System belastbar. Wenn die KI unsicher ist, werden Schadenfälle mit vollem Kontext an menschliche Prüfer weitergeleitet – die Tracing-Schicht liefert die Entscheidungskette, die Retrieval-Schicht zeigt ähnliche Fälle, der Semantic Layer stellt sicher, dass der Prüfer dieselben Definitionen sieht, die die KI genutzt hat. Die Modell-Schicht ist tauschbar; einfache Schadenfälle an ein leichteres Modell und komplexe Schadenfälle an ein leistungsfähigeres Modell zu routen, ist eine Architekturentscheidung – keine Neuentwicklung.
Das Ergebnis ist keine marginale Verbesserung gegenüber monolithischer Schadenfallbearbeitung. Es ist der Unterschied zwischen einer fragilen Demo und einem Produktionssystem, das in großem Maßstab echtes Geld bewegt.
Strategische Erkenntnis
Der KI-Stack ist kein Anbieterargument. Er ist ein Architekturmuster. So wie das OSI-Modell das Internet ermöglicht hat, indem es Schichten standardisierte, wird der entstehende KI-Stack Enterprise-KI ermöglichen, indem er jede Schicht unabhängig verbesserbar und ersetzbar macht.
Die Unternehmen, die das richtig machen, werden nicht die mit dem besten Modell sein. Es werden die mit dem besten Stack sein – mit klarer Verantwortung pro Schicht, sauberen Schnittstellen und einem Upgrade-Pfad, der nicht erfordert, alles darüber neu zu schreiben. So sieht AI-native Architektur tatsächlich aus.
Quellen
- Anthropic Claude Release Notes (Feb 2026)
- Model Context Protocol (MCP) Introduction
- Weaviate Blog – Agent Skills (Feb 2026)
- Qdrant 1.17 Release (Feb 2026)
- OSI-Modell – Wikipedia
- Lemonade Sets New World Record – Lemonade Blog
Daniel Piatkowski — Data & Analytics-Veteran, der AI-native Unternehmen prägt. elicify.ai