Ausgangslage
Der Semantic Layer war schon immer eine gute Idee. Kennzahlendefinitionen zentralisieren, damit das Reporting konsistent bleibt. Nützlich. Wichtig sogar. Aber keine besonders aufregende Infrastruktur.
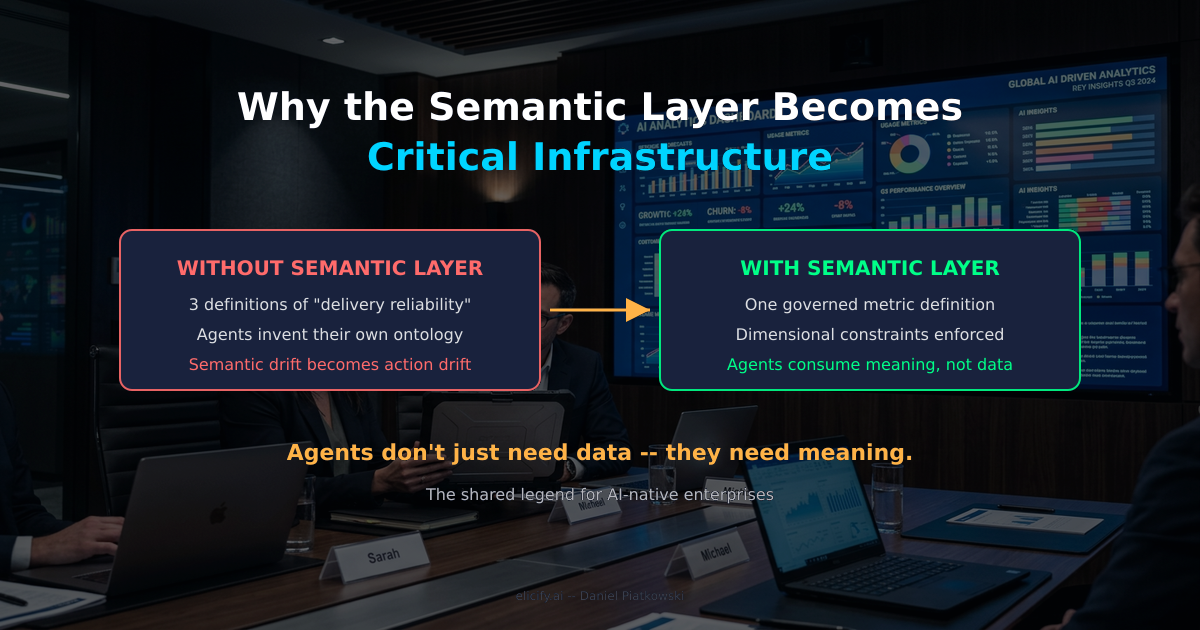
Das hat sich in dem Moment geändert, in dem wir angefangen haben, Agenten mit Produktivdaten arbeiten zu lassen. Ein Agent, der Umsatz abfragt, muss wissen, was Umsatz bedeutet – welche Entitäten, welche Zeitgrenzen, welche Ausschlüsse. Liegt er hier falsch, produziert er nicht nur ein schlechtes Diagramm. Er handelt falsch. Der Semantic Layer hat sich still und leise von einer Reporting-Hilfe zur Sicherheitsinfrastruktur für Agenten entwickelt. Den meisten Unternehmen ist das noch nicht aufgefallen.
Das Problem: Agenten ohne gemeinsame Bedeutung
Hier zeigt sich das Problem. Ein Beschaffungs-Agent soll Lieferantenrisiken anhand der „Lieferzuverlässigkeit“ bewerten. Nur: Lieferzuverlässigkeit hat im Unternehmen drei Definitionen. Die Logistik misst sie als Pünktlichkeitsquote gegenüber dem ursprünglich zugesagten Liefertermin, das Finanzwesen als Anteil der Rechnungen, die zu Bestellungen passen, und Operations rechnet anhand revidierter Lieferfenster. Der Agent wählt eine. Niemand weiß, welche.
Das ist nicht hypothetisch. Stellen Sie sich einen mittelständischen Händler vor, dessen Bestands-Agent sechs Wochen lang Überbestände bestellt, weil er die „Sell-Through-Rate“ anders berechnet als das Merchandising-Team. Die Zahlen sehen plausibel aus. Die Logik ist in sich schlüssig. Die Bedeutung ist falsch. Genau diese Art von Fehlern tritt in dem Moment auf, in dem Agenten auf Basis ungesteuerter Definitionen handeln.
Das eigentliche Problem liegt tiefer: Ohne einen gemeinsamen semantischen Vertrag erfindet jeder Agent faktisch seine eigene Ontologie. Multiplizieren Sie das mit einem Dutzend Agenten, und Sie erhalten ein Unternehmen, in dem automatisierte Systeme ihre Entscheidungen auf Basis inkompatibler Definitionen derselben Geschäftskonzepte treffen. Aus semantischer Drift wird Handlungsdrift. Der Agent ist nicht defekt – er arbeitet sauber mit einer Definition, der niemand zugestimmt hat.
Die dbt-Dokumentation zum Semantic Layer bringt es auf den Punkt: Der Semantic Layer existiert, um sicherzustellen, dass Kennzahlendefinitionen konsistent sind, unabhängig davon, wer – oder was – sie abfragt. Der „was“-Teil ist neu. Und er verändert alles daran, wie wir über diese Infrastruktur denken müssen.
Die Lösung: Der Semantic Layer als Vertrag für Agenten
Eine Analogie aus der Kartografie hilft. Bevor es standardisierte Kartenprojektionen und gemeinsame Legenden gab, zeichnete jeder Kartograf Karten mit eigenen Symbolen und Maßstäben. Zwei Karten derselben Küste konnten völlig unterschiedlich aussehen. Die Navigation zwischen ihnen war ein Ratespiel. Die Mercator-Projektion hat nicht nur die Visualisierung standardisiert – sie hat eine gemeinsame Sprache geschaffen, die Koordination zwischen Schiffen, Häfen und Nationen überhaupt erst möglich machte.
Dasselbe leistet der Semantic Layer für Agenten. Er ist die gemeinsame Legende.
So sieht das in der Praxis aus. Ein gut umgesetzter Semantic Layer liefert drei Fähigkeiten, die für agentische Architekturen entscheidend sind:
Gesteuerte Kennzahlendefinitionen. Umsatz, Churn, Auslastung, Marge – jede Kennzahl hat genau eine Definition, versionskontrolliert und auditierbar. Agenten berechnen keine Kennzahlen; sie konsumieren sie. Das ist eine entscheidende Einschränkung. Der Agent darf „Q4-Umsatz für die Nordics-Region“ abfragen, aber er darf keine eigene Umsatzformel erfinden.
Dimensionale Kontextgrenzen. Der Semantic Layer definiert nicht nur, was eine Kennzahl ist – er definiert auch, wie sie aufgeschlüsselt werden darf. Umsatz lässt sich nach Region, Produktlinie und Kundensegment aufschlüsseln. Nicht aber nach einzelnen Mitarbeitenden (eine Datenschutz-Schranke) oder nach experimenteller Kohorte (eine analytische Schranke). Diese Grenzen regeln, welche Fragen ein Agent beantworten darf.
Zeitliche Konsistenz. Ist „dieses Quartal“ ein Kalenderquartal oder ein Geschäftsquartal? Vergleicht „Year-over-Year“ den gleichen Kalenderzeitraum oder die gleichen Handelstage? Der Semantic Layer löst zeitliche Mehrdeutigkeit auf, bevor sie den Agenten erreicht – nicht erst, nachdem er einen irreführenden Vergleich produziert hat.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph LR
A["Agenten-Anfrage:\nQ4-Umsatz nach Region"] --> SL["Semantic Layer"]
SL --> MD["Kennzahlendefinition\n(eine Formel, versioniert)"]
SL --> DC["Dimensionale Einschränkungen\n(nur erlaubte Aufschlüsselungen)"]
SL --> TC["Zeitliche Auflösung\n(Geschäftsjahres-Q4, nicht Kalender-Q4)"]
MD --> R["Gesteuertes Ergebnis"]
DC --> R
TC --> R
R --> ACT["Agent handelt auf Basis\nkonsistenter Bedeutung"]
style SL fill:#1a2540,stroke:#00d4ff,color:#00d4ff,stroke-width:2px
style MD fill:#1a2540,stroke:#ffb347,color:#ffb347
style DC fill:#1a2540,stroke:#ffb347,color:#ffb347
style TC fill:#1a2540,stroke:#ffb347,color:#ffb347
style R fill:#0a2a1e,stroke:#00ff88,color:#00ff88,stroke-width:2px
style ACT fill:#0a2a1e,stroke:#00ff88,color:#00ff88
style A fill:#1a2540,stroke:#ffffff,color:#ffffff
Frameworks wie OpenClaw behandeln den Semantic Layer als genau diesen Vertrag: Agenten dürfen Daten abfragen, aber sie dürfen nur auf Basis definierter Bedeutung handeln. NemoClaw erzwingt gesteuerte Kontextgrenzen. In diese Richtung bewegt sich das Ökosystem – der Semantic Layer als Governance-Schicht, nicht mehr als bloße Reporting-Hilfe.
Umsetzung: So wird es konkret
Ich sage es offen: Das ist schwerer, als es klingt. In den meisten Unternehmen sind Kennzahlendefinitionen über BI-Tools, SQL-Views, Python-Notebooks und informellem Erfahrungswissen verteilt. Sie zu konsolidieren ist genauso ein politisches Projekt wie ein technisches. Die Umsatzzahl des Finanzwesens und die Umsatzzahl des Vertriebs unterscheiden sich aus Gründen – und diese Gründe haben Stakeholder.
So würde ich vorgehen:
Schritt 1: Auditieren Sie Ihre Kennzahlenlandschaft. Wählen Sie die zehn Schlüsselkennzahlen, die für Ihr Geschäft am wichtigsten sind. Dokumentieren Sie zu jeder Kennzahl jede aktuell verwendete Definition, wo sie gepflegt ist und wer sie verantwortet. Sie werden Duplikate finden. Sie werden Widersprüche finden. Das ist der Punkt.
Schritt 2: Etablieren Sie einen einzigen Semantic Layer. Der Semantic Layer von dbt liefert einen praktikablen Ausgangspunkt: Kennzahlen als Code definieren, versionskontrolliert ablegen und über eine konsistente API verfügbar machen. Databricks baut Metric Views nach derselben Philosophie: zentralisiert, gesteuert, abfragbar. Das Tooling existiert. Die harte Arbeit ist die organisatorische Einigung darüber, was jede Kennzahl bedeutet.
Schritt 3: Geben Sie Agenten Zugriff auf den Semantic Layer, nicht auf die Rohdaten. Das ist die entscheidende Architekturentscheidung. Ihre Agenten sollten keinen SQL-Zugriff auf die zugrunde liegenden Tabellen haben. Sie sollten die Semantic-Layer-API abfragen, die gesteuerte Kennzahlen samt dimensionalem Kontext zurückgibt. Der Agent bekommt Antworten – kein Rohmaterial, aus dem er sich seine eigenen zusammenbaut.
Schritt 4: Versionieren und auditieren. Wenn sich eine Kennzahlendefinition ändert – und das wird sie –, sollte der Semantic Layer diese Änderung explizit versionieren. Agenten, die die Kennzahl verwenden, sollten protokollieren, welche Version sie verwendet haben. So entsteht ein Audit-Trail, der die Frage beantwortet, die jede Aufsichtsbehörde irgendwann stellen wird: „Auf welcher Grundlage hat das System diese Entscheidung getroffen?“
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph TD
A1["Schritt 1: Audit\n10 Schlüsselkennzahlen"] --> A2["Schritt 2: Metrics-as-Code\nzentralisieren"]
A2 --> A3["Schritt 3: Agenten-Zugriff\nnur über Semantic API"]
A3 --> A4["Schritt 4: Jede Definitionsänderung\nversionieren und auditieren"]
A1 -.- N1["Widersprüche finden\nin BI, SQL, Notebooks"]
A2 -.- N2["dbt Semantic Layer\nDatabricks Metric Views"]
A3 -.- N3["Kein direkter SQL-Zugriff\nauf Rohdaten für Agenten"]
A4 -.- N4["Audit-Trail für\nregulatorische Compliance"]
style A1 fill:#1a2540,stroke:#00d4ff,color:#00d4ff,stroke-width:2px
style A2 fill:#1a2540,stroke:#00d4ff,color:#00d4ff,stroke-width:2px
style A3 fill:#1a2540,stroke:#00d4ff,color:#00d4ff,stroke-width:2px
style A4 fill:#1a2540,stroke:#00d4ff,color:#00d4ff,stroke-width:2px
style N1 fill:#1a2540,stroke:#ffb347,color:#ffb347,stroke-dasharray:5
style N2 fill:#1a2540,stroke:#ffb347,color:#ffb347,stroke-dasharray:5
style N3 fill:#1a2540,stroke:#ff6b6b,color:#ff6b6b,stroke-dasharray:5
style N4 fill:#1a2540,stroke:#00ff88,color:#00ff88,stroke-dasharray:5
Ich bin mir nicht sicher, ob Schritt 2 in Unternehmen mit Hunderten von Kennzahlen und einer langen politischen Geschichte rund um Definitionen sauber skaliert. Das Tooling deckt die technische Seite ab. Die organisatorische Verhandlung – wer die „wahre“ Definition von Customer Lifetime Value verantwortet – ist die Stelle, an der die meisten Umsetzungen ins Stocken geraten. Planen Sie Zeit dafür ein.
Beispiel: Wie ungesteuerte Semantik in der Schadenbearbeitung aussieht
Lemonade, der AI-first-Versicherer, hat seinen Ruf auf Geschwindigkeit aufgebaut – berühmt für die Schadenregulierung in drei Sekunden mithilfe seines KI-Schadenbots. Diese Geschwindigkeit ist nur möglich, weil Lemonade seine Kennzahlendefinitionen durchgängig kontrolliert. „Schadenkomplexität“ bedeutet im gesamten System dasselbe, weil das Unternehmen es von Anfang an so konzipiert hat.
Stellen Sie sich nun den typischen Versicherer vor, der Ähnliches versucht. Underwriting definiert Schadenkomplexität anhand von Deckungsüberschneidungen. Die Betrugserkennung definiert sie anhand von Musteranomalien. Die Schadenabwicklung definiert sie anhand der geschätzten Bearbeitungszeit. Ein agentisches Triage-System, das eine dieser Definitionen wählt – diejenige, die es zuerst im Datenkatalog findet –, leitet Schadenfälle widersprüchlich weiter. Schadenfälle mit niedriger Komplexität, aber ungewöhnlichen Mustern gelangen ins Schnellverfahren. Tatsächlich komplexe Schadenfälle mit unauffälligen Mustern landen in der Untersuchung.
Die Lösung ist ein gesteuerter Semantic Layer mit einer einzigen Kennzahl „Schadenkomplexität“ – einem zusammengesetzten Score, der alle drei Perspektiven mit vereinbarter Gewichtung integriert. Wenn die Definition aktualisiert werden muss, ändert sie sich an einer Stelle, und das Verhalten jedes Agenten ändert sich konsistent. Lemonades Vorteil ist nicht nur KI-Geschwindigkeit. Es ist semantische Klarheit, die fest in die Architektur eingebaut ist.
Strategische Kernaussage
Der Semantic Layer ist keine Reporting-Annehmlichkeit mehr. Er ist der Vertrag zwischen der vereinbarten Realität Ihrer Organisation und den Agenten, die auf Basis dieser Realität handeln. Ohne ihn setzen Sie Agenten in eine Welt, in der jedes automatisierte System sein eigenes privates Wörterbuch mit sich führt. Das ist kein Effizienzproblem. Das ist eine Governance-Krise, die nur darauf wartet, sichtbar zu werden.
Behandeln Sie den Semantic Layer als kritische Infrastruktur. Ihre Agenten tun es bereits.
Quellen
- dbt, Understanding the Semantic Layer, Dezember 2025
- Gartner, Agentic AI Predictions 2025-2027, März 2025
Daniel Piatkowski — Data & Analytics-Veteran, der AI-native Unternehmen prägt. — elicify.ai