The Most Expensive Library in the World
Your data platform is a library. A magnificent, petabyte-scale, meticulously catalogued library. And nobody is making decisions with it fast enough.
The World Economic Forum's AI at work research projects that AI will displace 92 million jobs globally by 2030 while creating 170 million new ones. The net gain is real, but only for organisations that can act on intelligence -- not just store it. MIT Sloan's research on scaling AI for results confirms what I keep seeing in the field: the gap between AI pilots and enterprise value is not a model problem. It is an architecture problem.
We spent fifteen years perfecting the plumbing. Data lakes, lakehouses, medallion architectures, streaming ingestion. All optimised for the same thing: making data available. Availability is table stakes now. The question is no longer "can I access the data?" It is "can the system make a good decision, in time, with appropriate oversight?"
That is a fundamentally different design problem. And most enterprise architectures are not built for it.
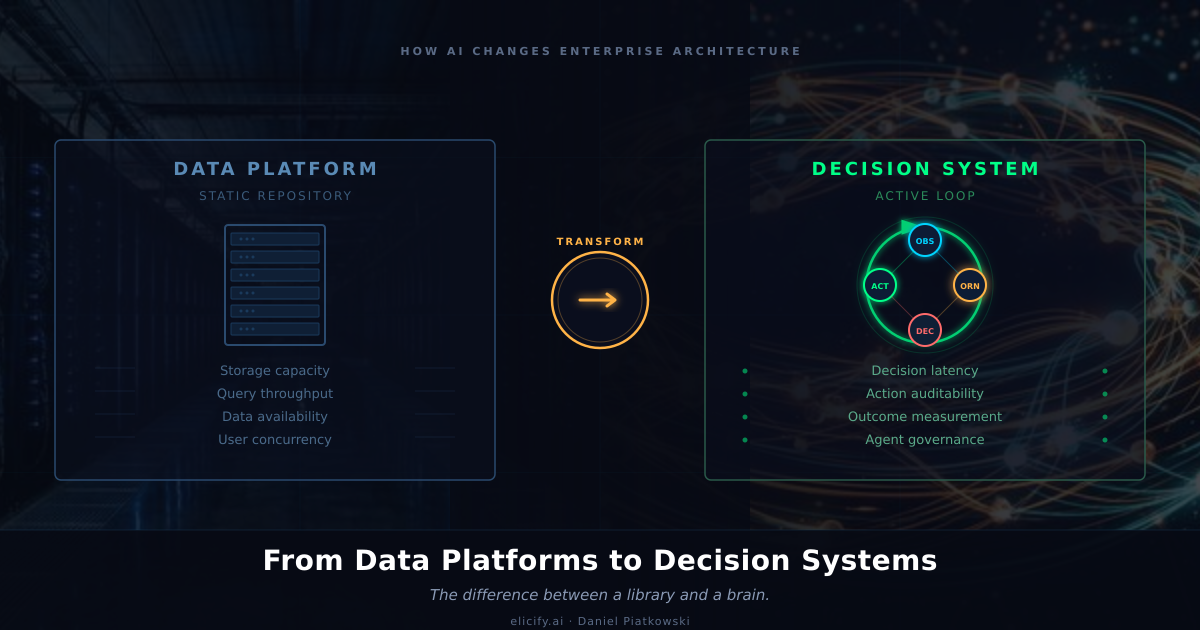
Diagnosis: What Data Platforms Actually Optimise For
Data platforms are infrastructure for storage, processing, and serving. They do this extraordinarily well. Databricks Unity Catalog, Snowflake's governance layer, the entire modern data stack -- all designed around a core assumption: humans are the decision-makers, and the platform's job is to get clean data to them.
This assumption shapes everything. Batch processing windows are acceptable because a human will review a dashboard tomorrow morning. Eventual consistency is fine because the analyst will notice if the numbers look wrong. Lineage tracking exists to satisfy auditors, not to feed autonomous agents with real-time provenance.
The architecture optimises for throughput and availability. How much data can we process? How quickly can we serve a query? How many concurrent users can access the warehouse? These are the right questions for a world where humans sit at the end of every data pipeline and apply judgement before acting.
That world is ending.
When an AI agent processes a customer refund, recommends a credit limit, or reroutes a supply chain, the data platform's guarantees are insufficient. The agent does not need yesterday's batch refresh. It needs current state, decision boundaries, audit trails, and feedback loops. It needs to know not just what the data says, but what authority it has, what the confidence threshold is, and where to escalate.
Consider what happens when a pricing agent operates on a 24-hour batch refresh while competitors adjust in real time. Three days of margin-destroying decisions before anyone notices. The model is fine. The architecture fails. This is not hypothetical -- it is the predictable consequence of running AI agents on infrastructure designed for human decision cadence.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph LR
subgraph DP["DATA PLATFORM (optimises for)"]
A1["Storage\nCapacity"]
A2["Query\nThroughput"]
A3["Data\nAvailability"]
A4["User\nConcurrency"]
end
subgraph DS["DECISION SYSTEM (optimises for)"]
B1["Decision\nLatency"]
B2["Action\nAuditability"]
B3["Outcome\nMeasurement"]
B4["Agent\nGovernance"]
end
DP -->|"Necessary but\nnot sufficient"| DS
style A1 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style A2 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style A3 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style A4 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style B1 fill:#1a2540,stroke:#ffb347,color:#ffffff
style B2 fill:#1a2540,stroke:#ffb347,color:#ffffff
style B3 fill:#1a2540,stroke:#ffb347,color:#ffffff
style B4 fill:#1a2540,stroke:#ffb347,color:#ffffff
style DP fill:#0a0f1e,stroke:#00d4ff,color:#00d4ff
style DS fill:#0a0f1e,stroke:#ffb347,color:#ffb347
Reframe: What Fighter Pilots Already Knew
In the 1950s, US Air Force Colonel John Boyd studied why American pilots in Korea achieved a 10:1 kill ratio despite flying aircraft with inferior turning radius. His answer was not about the planes. It was about decision speed.
Boyd developed the OODA loop: Observe, Orient, Decide, Act. The pilot who cycled through this loop faster won the engagement -- not because they had better weapons, but because they operated inside the adversary's decision cycle. By the time the enemy oriented to the new situation, the situation had already changed again.
Enterprise AI architecture is converging on the same pattern without naming it.
Every agentic system I have seen work in production follows Boyd's loop. The agent observes (ingests current state from streaming data, APIs, events). It orients (applies context -- business rules, historical patterns, confidence thresholds). It decides (selects an action within its authority boundary). It acts (executes the decision and captures the outcome). Then the outcome feeds back into observation, and the loop continues.
The parallel is not decorative. Boyd's key insight was that the orient phase -- where you synthesise information against your mental model -- is where competitive advantage lives. In enterprise AI, orientation is where the agent applies governance, context, and domain knowledge. Get this wrong and you have a fast system making confidently bad decisions. Get it right and you have something that genuinely outperforms human decision-making at speed.
I'm not sure this maps perfectly to every enterprise use case. Some decisions should be slow and deliberative. But for the 80% of operational decisions that follow known patterns with clear boundaries, the OODA architecture is remarkably effective.
Framework: The Decision Loop Architecture
Here is the model. A decision system has four layers, each corresponding to a phase of the loop. The data platform does not disappear -- it becomes the foundation that the decision layers sit on.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph TD
O["OBSERVE\nStreaming ingestion, event capture,\nreal-time state"] --> OR["ORIENT\nContext engine: rules, thresholds,\nhistorical patterns, confidence scores"]
OR --> D["DECIDE\nAgent selects action within\nauthority boundary"]
D --> A["ACT\nExecute decision, capture outcome,\nlog full trace"]
A -->|"Feedback loop"| O
DP["DATA PLATFORM\nStorage, processing, governance,\ncatalogue"] -.->|"Feeds"| O
A -.->|"Outcomes stored"| DP
style O fill:#1a2540,stroke:#00d4ff,color:#ffffff,stroke-width:2px
style OR fill:#1a2540,stroke:#ffb347,color:#ffffff,stroke-width:2px
style D fill:#1a2540,stroke:#00ff88,color:#ffffff,stroke-width:2px
style A fill:#1a2540,stroke:#ff6b6b,color:#ffffff,stroke-width:2px
style DP fill:#0a0f1e,stroke:#ffffff,color:#ffffff,stroke-width:1px
Layer 1: Observe. Replace batch ETL as the primary input with streaming event capture. The data platform still handles heavy analytical workloads, but the decision system needs current state. This means Change Data Capture from operational systems, event streams from customer interactions, real-time market feeds. Databricks Delta Live Tables or Snowflake Streams handle this well -- the technology exists. The gap is that most enterprises still treat streaming as an exception rather than the default input path.
Layer 2: Orient. This is the layer most architectures lack entirely. Orientation is where raw signals become decision-ready context. It includes business rules (this customer is in a regulated segment), historical patterns (similar requests resulted in chargeback 30% of the time), confidence calibration (the model is 72% certain -- is that above the threshold for autonomous action?), and authority boundaries (the agent can approve up to EUR 5,000; above that, escalate). Without this layer, agents make decisions in a vacuum.
Layer 3: Decide. The agent selects and commits to an action. Frameworks like OpenClaw and LangGraph encode this as the agent runtime: plan, execute tools, verify evidence, continue. The critical design choice is making every decision explicit and logged -- not just the action, but the reasoning, the alternatives considered, and the confidence level. This is what makes the system auditable.
Layer 4: Act. Execute the decision and close the loop. The outcome -- did the refund reduce churn? did the rerouted shipment arrive on time? -- feeds back into the observation layer. This is how the system learns. Not through periodic model retraining, but through continuous measurement of decision quality.
The hardest part is not building any single layer. It is connecting them into a continuous loop with consistent governance throughout. Most enterprises I work with have fragments: they have streaming somewhere, they have an agent prototype somewhere else, they have a rules engine in yet another system. The integration is the architecture.
Application: Lemonade's Claims Decision Loop
Lemonade Insurance built exactly this architecture with their AI claims agent, AI Jim. Previously, insurance claims followed the standard industry pipeline: arrive, queue, human reviews against policy terms. Straightforward cases consumed the same review time as complex incidents.
Lemonade did not bolt an AI agent onto the existing process. They redrew the architecture around the decision.
Observe: Claims enter via their app -- photo uploads, incident descriptions, structured data capture. All captured as events feeding the AI decision pipeline in real time, not batch.
Orient: AI Jim enriches each claim with context: policy coverage lookup, fraud risk scoring (based on historical claim patterns), damage assessment via computer vision, and an authority matrix defining what the agent can approve autonomously.
Decide: For claims within defined parameters -- standard coverage, fraud risk below threshold -- AI Jim approves and triggers payment. The record: a claim settled in 2 seconds. Above these thresholds, the claim routes to a human adjuster with the full context pre-assembled. The agent does not just flag -- it explains why it escalated.
Act: Payment triggers, customer notification sends, and the outcome (claim reopened? customer complained? fraud detected later?) feeds back into the model. 96% of first notices of loss are now handled by AI, with 55% of claims processed fully autonomously.
The tradeoff is significant upfront investment in the orientation layer -- encoding business rules, thresholds, and escalation logic into the architecture rather than leaving them in adjusters' heads. That knowledge capture was the real project. The AI part was comparatively straightforward.
%%{init: {'theme': 'base', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#ffffff', 'lineColor': '#ffffff', 'background': '#0a0f1e', 'mainBkg': '#1a2540', 'nodeBorder': '#ffffff', 'edgeLabelBackground': '#1a2540'}}}%%
graph LR
subgraph BEFORE["BEFORE: Pipeline Architecture"]
C1["Claim\narrives"] --> Q1["Queue\n(days)"] --> H1["Human\nreviews all"] --> P1["Payment\nor reject"]
end
subgraph AFTER["AFTER: Decision Loop"]
C2["Claim\nevent"] --> CTX["Orient:\ncontext engine"] --> DEC{"Decide:\nwithin\nboundary?"}
DEC -->|"Yes"| AUTO["Auto-approve\n< 4 hours"]
DEC -->|"No"| HUM["Human +\nfull context"]
AUTO --> FB["Feedback\nloop"]
HUM --> FB
FB -->|"Outcomes"| CTX
end
style C1 fill:#1a2540,stroke:#ffffff,color:#ffffff
style Q1 fill:#2a1a1a,stroke:#ff6b6b,color:#ff6b6b
style H1 fill:#1a2540,stroke:#ffffff,color:#ffffff
style P1 fill:#1a2540,stroke:#ffffff,color:#ffffff
style C2 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style CTX fill:#1a2540,stroke:#ffb347,color:#ffffff
style DEC fill:#1a2540,stroke:#00ff88,color:#ffffff
style AUTO fill:#0a2a1e,stroke:#00ff88,color:#00ff88
style HUM fill:#1a2540,stroke:#00d4ff,color:#ffffff
style FB fill:#1a2540,stroke:#ffb347,color:#ffffff
style BEFORE fill:#0a0f1e,stroke:#ff6b6b,color:#ff6b6b
style AFTER fill:#0a0f1e,stroke:#00ff88,color:#00ff88
Implication: Architecture Is the Strategy
The shift from data platforms to decision systems is not a technology upgrade. It is an architectural reorientation around a different unit of value. The data platform asks: how do we manage information? The decision system asks: how do we produce good outcomes, fast, with auditability?
Every enterprise already has the data infrastructure. What they lack is the orientation layer -- the encoded business knowledge, the authority boundaries, the feedback loops that turn raw data into governed action. That layer is the new competitive advantage. Not the model, not the data, not the compute. The architecture of the decision itself.
Sources
- World Economic Forum, AI at Work Insights, January 2025
- MIT Sloan Management Review, Scaling AI for Results, January 2025
- John Boyd, "Patterns of Conflict" (1986) -- original OODA loop doctrine
- Lemonade Insurance: AI Jim sets new world record
Daniel Piatkowski Data & Analytics veteran shaping AI-native enterprises elicify.ai