Business Context: The Platform Fight Has Shifted
Every major platform war -- cloud compute, data warehousing, BI tooling -- was ultimately about control points. Not features. The company that controlled where developers built, where data landed, or where dashboards lived captured the ecosystem.
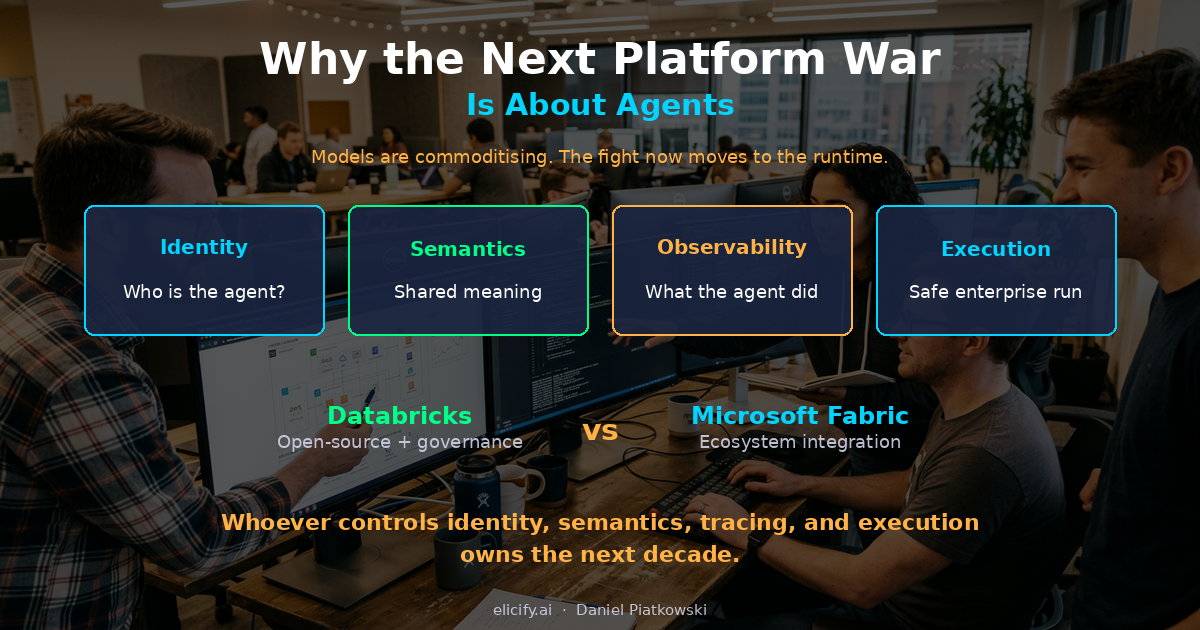
The same logic now applies to AI agents. Agents need to authenticate, call tools, interpret data, and be observed. Whoever controls that runtime layer -- the plumbing between the model and the enterprise -- owns the next decade of platform economics. Databricks knows this. Microsoft knows this. The race is on.
The Problem: Agents Without a Home
Here is what happens when you build agents today. You pick a model. You pick a framework -- LangChain, CrewAI, Autogen, something custom. You wire up tool access with API keys stored in environment variables. You hardcode permissions. You deploy it somewhere, maybe a container, maybe a notebook, maybe a Lambda function.
It works in the demo. Then production hits.
The agent needs to call a Salesforce API, but the OAuth token expired. It needs to query a Snowflake table, but the service account has broader permissions than it should. It writes to a CRM field, but there is no audit trail showing why. When the agent hallucinates a tool call, nobody can trace the decision chain.
This is not an edge case. It is the default state of agent deployment in most enterprises today. The model works fine. The runtime around it is duct tape.
The Model Context Protocol (MCP) emerged to standardise how agents discover and use tools -- a shared interface between models and the systems they interact with. But MCP alone does not solve authentication, governance, or observability. It standardises the shape of the connection. The platform war is about who fills in the substance.
The Solution: Four Control Points That Define the Agent Runtime
The agent runtime war comes down to four control points. Whoever nails all four wins.
%%{init: {'theme': 'dark', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#00d4ff', 'lineColor': '#ffffff', 'secondaryColor': '#1a2540', 'tertiaryColor': '#1a2540', 'edgeLabelBackground': '#0a0f1e', 'clusterBkg': '#0a0f1e', 'clusterBorder': '#ffffff', 'fontFamily': 'arial', 'fontSize': '14px'}}}%%
graph TD
A["Agent Request"] --> B["1. Identity & Permissions
Who is this agent? What can it access?"]
B --> C["2. Semantic Meaning
Does the agent understand the data it touches?"]
C --> D["3. Evaluation & Tracing
Can we observe every decision and tool call?"]
D --> E["4. Reliable Execution
Does it run consistently at scale?"]
E --> F["Enterprise-Grade Agent"]
style A fill:#1a2540,stroke:#ffb347,color:#ffffff
style B fill:#1a2540,stroke:#00d4ff,color:#ffffff
style C fill:#1a2540,stroke:#00d4ff,color:#ffffff
style D fill:#1a2540,stroke:#00d4ff,color:#ffffff
style E fill:#1a2540,stroke:#00d4ff,color:#ffffff
style F fill:#1a2540,stroke:#00ff88,color:#ffffff
1. Identity and permissions. The agent must authenticate as a governed identity -- not a shared service account, not a hardcoded API key. Databricks shipped managed OAuth for MCP servers in their March 2026 release, which means agents connecting to Unity Catalog-governed tools inherit the same access controls as human users. This is a significant move. It means the agent's permissions are auditable, revocable, and tied to governance policies that already exist. No separate agent-permission silo.
2. Semantic meaning. An agent that can call a tool is not the same as an agent that understands what the data means. This is where the semantic layer becomes critical infrastructure. When an agent queries "revenue," it needs to know whether that means ARR, MRR, or recognised revenue -- and it needs to get the right definition without a human clarifying each time. Platforms that own the semantic layer (Unity Catalog's metadata, Snowflake Cortex's semantic model) have a structural advantage here.
3. Evaluation and tracing. When an agent makes a bad call -- and it will -- you need a full trace. Which tool did it call? What data did it receive? What reasoning chain produced the output? This is observability for agents, and it is harder than application observability because the decision logic is probabilistic. Databricks MLflow Tracing and Microsoft Fabric's agent monitoring are both investing here, but neither has solved it completely. I'm not sure anyone has.
4. Reliable execution. The agent must run consistently at enterprise scale. Retries, timeouts, rate limits, graceful degradation. This sounds boring. It is also where most agent projects die. A demo agent can crash and restart. A production agent processing thousands of customer interactions per hour cannot.
Implementation: How the Platforms Are Positioning
The moves are already happening. Here is how I read the competitive positioning.
%%{init: {'theme': 'dark', 'themeVariables': {'primaryColor': '#1a2540', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#00d4ff', 'lineColor': '#ffffff', 'secondaryColor': '#1a2540', 'tertiaryColor': '#1a2540', 'edgeLabelBackground': '#0a0f1e', 'clusterBkg': '#0a0f1e', 'clusterBorder': '#ffffff', 'fontFamily': 'arial', 'fontSize': '14px'}}}%%
graph LR
subgraph DB["Databricks"]
D1["Unity Catalog
Identity + Semantics"]
D2["MCP OAuth
Tool Auth"]
D3["MLflow Tracing
Observability"]
D4["Mosaic AI
Execution"]
end
subgraph MS["Microsoft Fabric"]
M1["OneLake
Unified Data"]
M2["Data Agents
Tool Integration"]
M3["Copilot Studio
Orchestration"]
M4["Purview
Governance"]
end
D1 --- D2 --- D3 --- D4
M1 --- M2 --- M3 --- M4
style D1 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style D2 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style D3 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style D4 fill:#1a2540,stroke:#00d4ff,color:#ffffff
style M1 fill:#1a2540,stroke:#ffb347,color:#ffffff
style M2 fill:#1a2540,stroke:#ffb347,color:#ffffff
style M3 fill:#1a2540,stroke:#ffb347,color:#ffffff
style M4 fill:#1a2540,stroke:#ffb347,color:#ffffff
style DB fill:#0a0f1e,stroke:#00d4ff,color:#ffffff
style MS fill:#0a0f1e,stroke:#ffb347,color:#ffffff
Databricks is playing the open-standards card. MCP for tool integration. OAuth for identity. Unity Catalog as the governance spine. Their bet: if the agent runtime is built on open protocols, customers choose Databricks because the governance and semantic layers are already there. The March 2026 release adding managed OAuth for MCP servers is a quiet but strategic move -- it makes Databricks the first platform where agent-to-tool authentication is a managed, governed service rather than a DIY integration.
Microsoft Fabric is playing the integration card. Data agents in Fabric connect directly to OneLake data, leverage Copilot Studio for orchestration, and plug into the Microsoft 365 ecosystem that most enterprises already live in. Their bet: agents need to operate where the users and data already are, and nobody has a larger installed base than Microsoft. The tradeoff is tighter coupling -- your agents become deeply Fabric-native, which is powerful until you need them to operate outside that ecosystem.
OpenClaw uses MCP-style boundaries so agents remain portable across platforms where identity and governance live. That portability question -- can your agent move between runtimes without being rebuilt? -- will separate lasting architectures from vendor lock-in.
Example: The Railroad Gauge Wars
This is not the first time an industry has fought over runtime standards. In the 1800s, American railroads operated on different track gauges. The Erie Railroad used 6-foot gauge. The standard in the South was 5 feet. The "standard gauge" of 4 feet 8.5 inches dominated in the Northeast.
The consequence was brutal. Cargo had to be physically unloaded and reloaded at every gauge boundary. Entire cities -- Chattanooga, Cairo, Illinois -- existed partly because they were transhipment points where gauges changed. The inefficiency was staggering, but each railroad resisted standardisation because their gauge was a competitive moat.
The parallel to agent platforms is precise, not decorative. Today, an agent built on Databricks' runtime cannot easily migrate to Fabric, and vice versa. Tool integrations, authentication flows, observability hooks -- they all differ. MCP is trying to become the standard gauge for AI tool integration. But a standard interface alone was not enough for railroads either. The real winner was the ecosystem that combined standard gauge with the best freight logistics, scheduling, and terminal infrastructure.
That is the race Databricks and Microsoft are running. The standard gauge matters. What you build on top of it matters more.
Strategic Takeaway
The model layer is commoditising. GPT-4o, Claude, Gemini -- they are converging in capability. The differentiation is moving down the stack to the agent runtime: who authenticates the agent, who governs its tool access, who traces its decisions, who ensures reliable execution.
If you are making platform bets today, stop evaluating model benchmarks. Start evaluating runtime control points. The platform that owns the agent runtime will own the AI-native enterprise -- the same way AWS owned cloud-native development by controlling compute, storage, and identity, not by building the best application.
Sources
- Databricks March 2026 Release Notes -- Managed OAuth for MCP servers, Unity Catalog agent governance
- Model Context Protocol (MCP) Introduction -- Open standard for agent-to-tool integration
- Microsoft Fabric Data Agents -- Fabric's approach to AI agent integration with OneLake
Daniel Piatkowski Data & Analytics veteran shaping AI-native enterprises elicify.ai